
ConTextTab
A Semantics-Aware Tabular In-Context Learner
Marco Spinaci, Marek Polewczyk, Maximilian Schambach, Sam Thelin — SAP
研究动机
弥合 Table-native ICL 与 LLM-based ICL 之间的鸿沟
表格数据的上下文学习(In-Context Learning, ICL)近年来取得了显著进展,但现有方法分为两个阵营,各有明显短板。ConTextTab 的核心动机在于融合两者的优势,构建一个既保留表格原生架构效率,又具备语义理解能力的统一框架。
在架构上高效且天然适配表格的二维结构,支持大量上下文行。但完全在合成数值数据上训练,无法利用列名、类别标签、自由文本或日期中的语义信息。
继承了大语言模型的世界知识和深层语义理解能力。但受限于文本序列化带来的 token 低效、极小的可用上下文(约 32 行),以及丢失表格的 2D 结构和置换不变性。
ConTextTab 的解决方案:在 table-native 的骨干架构上,引入预训练语义嵌入来编码单元格值和列名,并在大规模真实世界表格语料(T4 数据集,2.18M 张表)上进行预训练。这使得模型既保持了高效的表格原生架构,又获得了对语义信息的深度理解。
三类方法详细对比
| 维度 | Table-native ICL | LLM-based ICL | ConTextTab |
|---|---|---|---|
| 训练数据 | 合成数值数据 | 真实世界表格(T4, 3M 表) | 真实世界表格(T4, 2.18M 表) |
| 语义理解 | 无(列名/类别值被忽略) | 强(继承 LLM 世界知识) | 强(预训练文本嵌入) |
| 上下文容量 | 大(~10,000 行) | 小(~32 行) | 大(默认 8,192 行) |
| Token 效率 | 高(直接嵌入) | 低(文本序列化) | 高(直接嵌入) |
| 表格结构保留 | 完整(2D 注意力) | 丢失(1D 序列化) | 完整(2D 注意力) |
| 置换等变性 | 是 | 否 | 是 |
| 代表方法 | TabPFN, TabICL | TabuLa-8B | ConTextTab |
模型架构总览
数据类型特定编码 → 交替注意力骨干 → 任务特定解码
ConTextTab 的架构由三个核心模块组成。首先,编码模块根据数据类型(文本、日期、数值)使用不同的嵌入策略,并将列名嵌入作为'位置编码'与单元格嵌入相加。然后,骨干网络采用交替的 cross-column 和 cross-row 自注意力层处理表格数据。最后,解码模块根据任务类型(分类或回归)输出预测结果。
编码模块
文本 → MiniLM 嵌入;日期 → Day/Month/Year 分别嵌入后相加;数值 → 裁剪+标准化+线性变换;列名 → 语义嵌入后与单元格相加
骨干网络
交替的 cross-column(无掩码,行内特征交互)和 cross-row(有掩码,行间上下文学习)自注意力层,12 层,768 维
解码模块
分类:MLP + cross-entropy loss;回归:预测标准化后的浮点值 + L₂ loss
关键设计选择:模型权重在各注意力块之间共享(类似 RNN 的迭代结构),将 172M 参数压缩至 16M 可训练参数,而实验表明这不影响性能。整个编码过程保持了行和列的置换等变性,这是表格数据的重要归纳偏置。
编码模块详解
四种数据类型,四种编码策略
ConTextTab 的核心创新之一是根据数据模态(文本、日期、数值)使用不同的嵌入策略。列名也被语义编码并与单元格嵌入相加,扮演类似'位置编码'的角色。点击下方各类型,查看具体的编码流程。
"Laptop"输入文本单元格值(如 "Laptop")
通过预训练文本嵌入模型(all-MiniLM-L6-v2)编码
得到语义向量(保留了 "Laptop" 的含义)
通过可学习线性层映射到目标维度 d
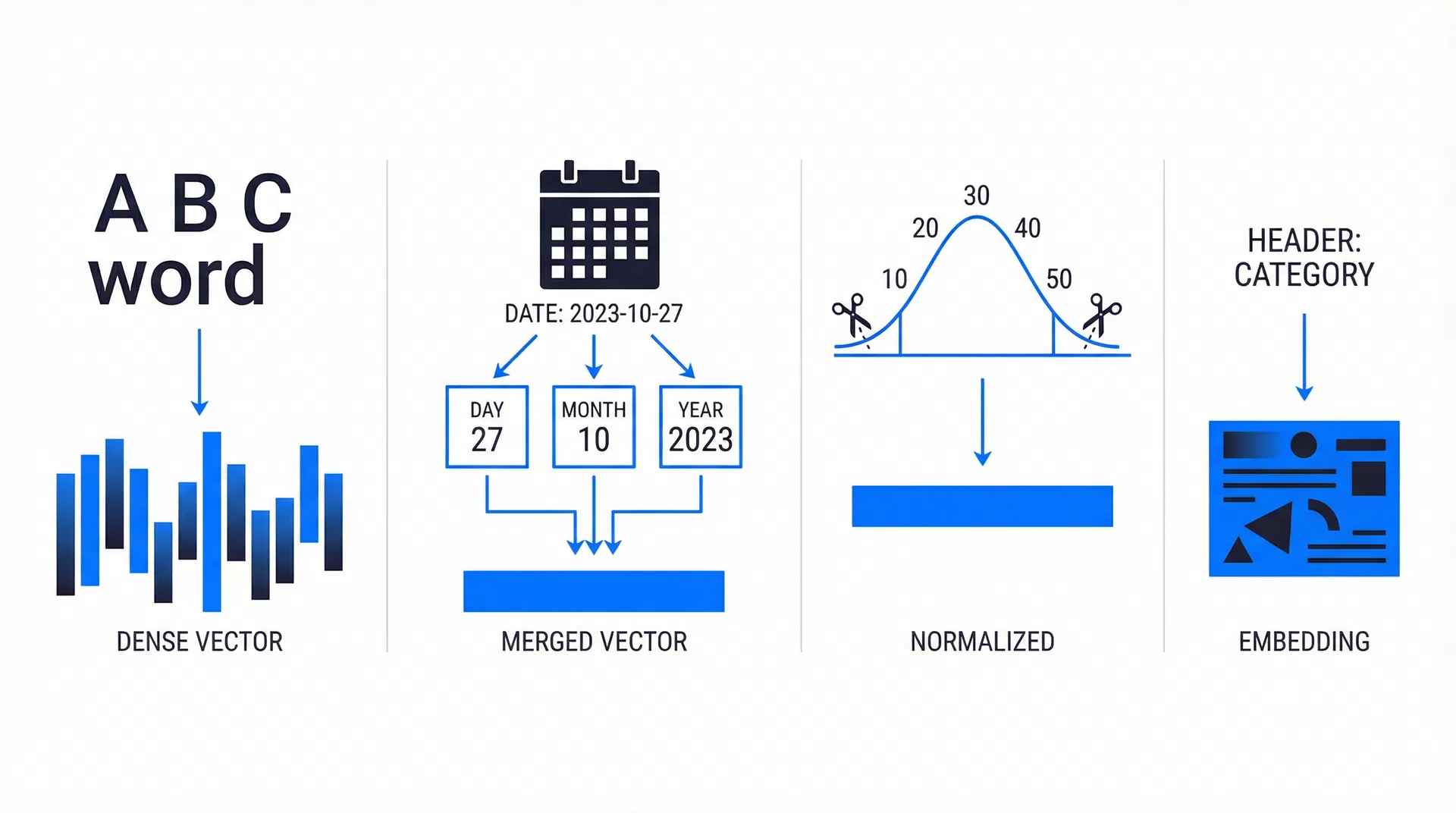
数值编码深入:裁剪与标准化
真实世界表格中充满异常值和噪声分布。ConTextTab 通过分位数裁剪和标准化来限制数值幅度,防止预训练过程中的梯度爆炸。拖动下方滑块,观察不同裁剪百分位对数据分布的影响。
注意力机制详解
Cross-column 与 Cross-row:表格 ICL 的核心
ConTextTab 的骨干网络交替使用两种自注意力机制。Cross-column attention(无掩码)允许同一行内所有特征自由交互,学习特征间的复杂关系。Cross-row attention(有掩码)确保 query 行只能从 context 行中学习,这正是实现 in-context learning 的关键。
悬停下方表格中的单元格,观察不同注意力模式下每个位置能'看到'哪些其他位置。
Cross-Column Attention(无掩码)
在同一行内,所有特征(列)之间可以自由交互。每一行被视为一个独立的 batch 元素。
这使得模型能够学习特征之间的复杂关系,例如'价格'与'描述'之间的关联。
悬停任意单元格,查看它能注意到哪些位置。
为什么 cross-row 掩码至关重要?如果 query 行能注意到其他 query 行,模型就可能'偷看'其他查询样本的标签,而非真正从 context 中学习。掩码机制强制执行了 ICL 的核心范式:从已标注的 (x, y) 上下文对中学习预测规则,然后应用到新的查询上。
训练与推理
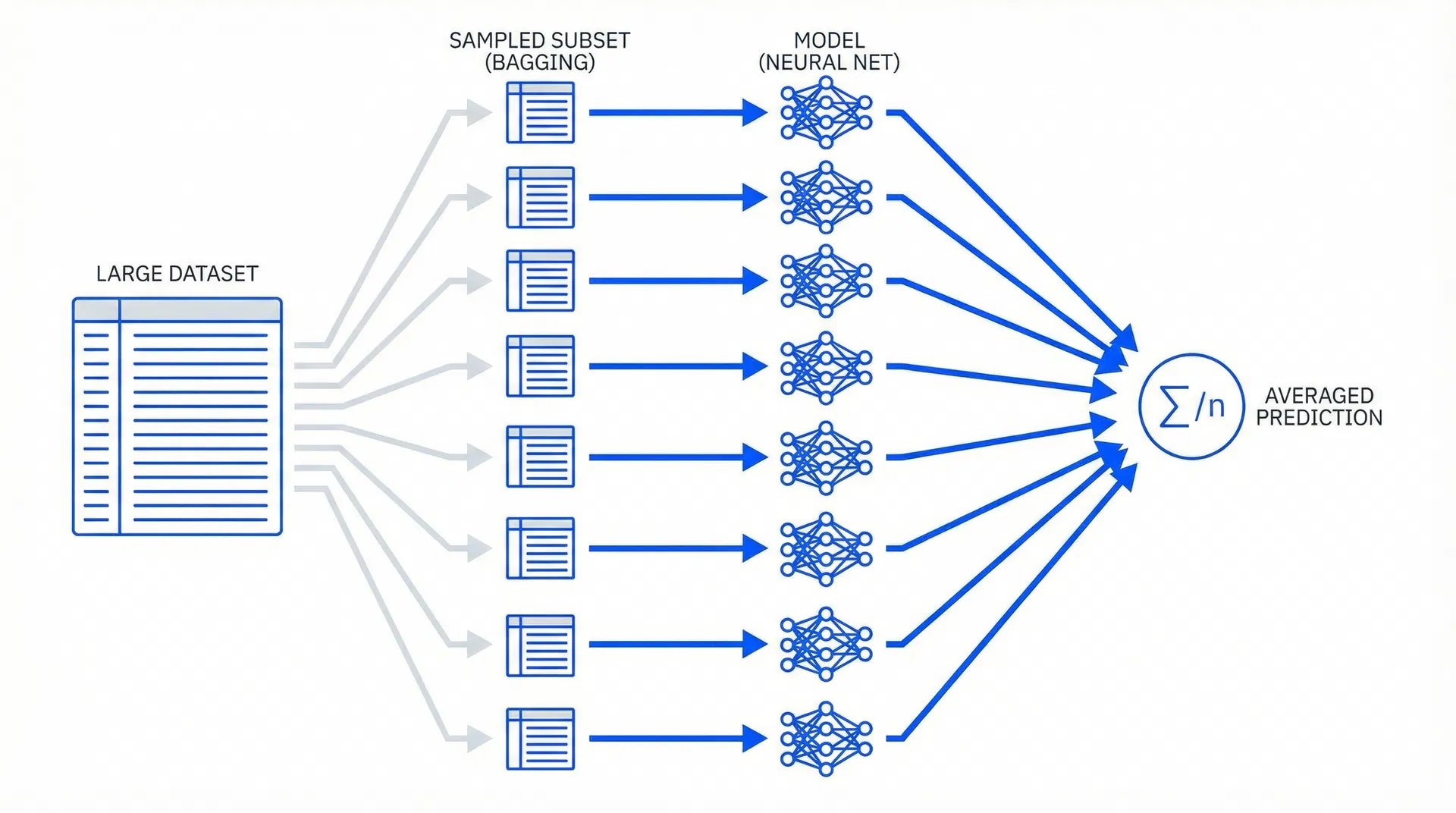
大规模预训练 + 8-fold Bagging 推理
8-fold Bagging 过程演示
推理时,模型从训练集中有放回地采样 8 次上下文,分别进行预测,最后聚合结果。这使得模型能够利用远超训练时上下文大小的数据量。点击按钮逐步查看采样过程。
实验结果
跨 5 个基准测试的全面评估
ConTextTab 在语义丰富的 CARTE 基准上设立了新的 SOTA,同时在非语义基准上与调优的 boosted trees 竞争力相当。切换下方的基准测试和指标,查看不同场景下的表现。
关键发现
语义是核心驱动力
消融实验表明,将语义编码替换为传统编码器(MinHash/GapEncoder)会导致 CARTE 上的显著性能下降。移除列名语义导致约 1% 准确率和 2% R² 的下降。
小数据场景优势明显
在 CARTE 基准的不同数据量子集上,ConTextTab 在 2048 行以下的所有规模上一致优于其他模型,甚至超越 AutoGluon。
大数据场景仍有挑战
所有 table-native ICL 模型在非常大的数据集上仍难以与调优的 boosted trees 和 AutoGluon 竞争。增加上下文和 bagging 并不能完全解决这一问题。
权重共享有效
注意力块之间的权重共享将参数从 172M 压缩至 16M,而实验表明这不影响甚至略微提升了性能。